![]()
 |
|
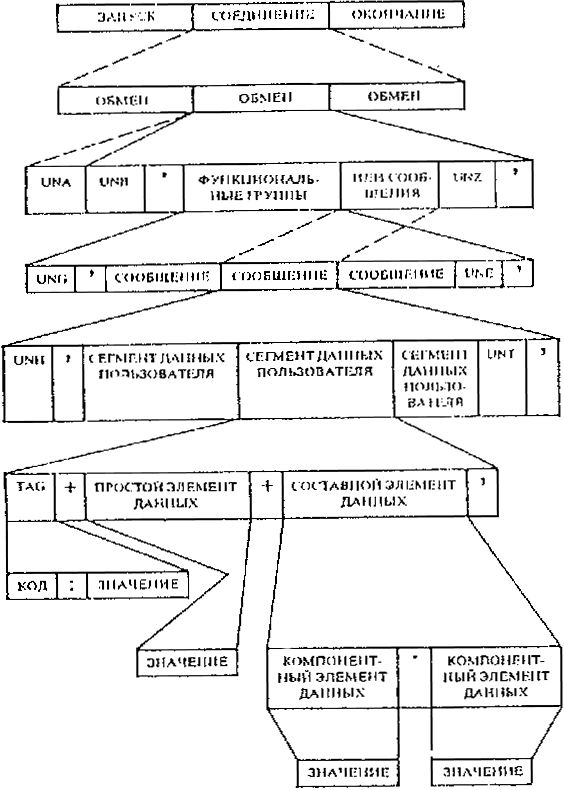
 |
||
|
|
|
|
|
|
|
ГОСТ 6.20.1-90 (ИСО 9735-88) Электронный обмен данными в управлении, торговле и на транспорте (ЭДИФАКТ) Синтаксические правила
СОДЕРЖАНИЕ 6. Повторение элементов данных 7. Последовательное размещение сегментов в сообщении 8. Представление значений цифровых элементов данных Приложение 1 обязательное Термины, используемые в настоящем стандарте, и их пояснения Приложение 2 обязательное Справочник служебных сегментов Приложение 3 обязательное Последовательность сегментов и групп сегментов в сообщении Приложение 4 справочное Справочные нормативные документы
ГОСУДАРСТВЕННЫЙ СТАНДАРТ СОЮЗА ССР ЭЛЕКТРОННЫЙ ОБМЕН ДАННЫМИ В УПРАВЛЕНИИ, ТОРГОВЛЕ И НА ТРАНСПОРТЕ (ЭДИФАКТ) Синтаксические правила EDI for administration, commerce and transport (EDIFACT). Syntax rules ГОСТ 6.20.1-90 (ИСО 9735-88) Дата введения 01.01.92 Настоящий стандарт устанавливает синтаксические правила построения сообщений, используемых в обмене информацией между партнерами. Стандарт распространяется на различные сферы народного хозяйства, в том числе применяется в управлении, внешней торговле и на транспорте. Стандарт обязателен для предприятий, организаций и учреждений, осуществляющих обмен данными в открытых системах. Термины, используемые в настоящем стандарте, приведены в приложении 1.
1.1. В настоящем стандарте устанавливаются синтаксические уровни А и В, функции которых идентичны за исключением используемых наборов знаков. По мере возникновения потребностей в дополнительных синтаксических функциях могут быть определены другие уровни. Уровень А использует набор знаков, указанный в п. 2.2.1. Уровень В использует набор знаков, указанный в п. 2.2.2. 1.2. Служебный сегмент UNA (согласованный набор ограничителей, см. приложение 2) устанавливает набор знаков (разделители и другие служебные знаки), которые используются при обмене. Если набор используемых служебных знаков отличается от наборов знаков уровней А и В, то эти знаки должны быть установлены партнерами по обмену на многосторонней или двусторонней основе и определены в сегменте UNA.
2.1. В передаваемой информации должны применяться установленные в настоящем разделе наборы знаков. 2.2. Для представления, знаков в указанных ниже наборах должны использоваться 7-битные коды ГОСТ 27463 (ИСО 646) или соответствующие 8-битные коды ИСО 6937/2 и ГОСТ 19753 (ИСО 8859). 2.2.1. Набор знаков синтаксического уровня А содержит следующие знаки: прописные буквы верхнего регистра латинского алфавита - А - Z цифры - 0 - 9 пробел точка - . запятая - , дефис или знак минуса - - левая скобка (открыть скобку) - ( правая скобка (закрыть скобку) - ) наклонная черта - / знак равенства - = Знаки, предназначенные для использования в качестве: Апостроф - ’ указателя конца сегмента знак плюс - + указателя начала сегмента и разделителя элементов данных двоеточие - : разделителя компонентных элементов данных в составном элементе данных вопросительный знак - ? знака отмены ПРИМЕЧАНИЕ. Вопросительный знак, непосредственно предшествующий одному из следующих знаков: апостроф (’), плюс (+), вопросительный знак (?) - восстанавливает их обычное значение. Например, 10?+10=20 означает 10+10=20. Вопросительный знак в собственном значении обозначается - ??. Следующие знаки являются частью набора знаков уровня А, однако они не должны использоваться в передаче сообщений по телексной связи. восклицательный знак - ! кавычки - » знак процента - % амперсенд (знак, обозначающий союз «и») - & звездочка - * точка с запятой - ; знак меньше, чем - < знак больше, чем - > 2.2.2. Набор знаков синтаксического уровня В содержит следующие знаки: прописные буквы верхнего регистра латинского алфавита - А - Z строчные буквы нижнего регистра латинского алфавита - а - z цифры - 0 - 9 пробел точка - . запятая - , дефис или знак минуса - - левая скобка (открыть скобку) - ( правая скобка (закрыть скобку) - ) наклонная черта - / апостроф – ’ знак плюс - + двоеточие - : знак равенства - = вопросительный знак - ? восклицательный знак - ! кавычки - » знак процента - % амперсенд - & звездочка - * точка с запятой - ; знак меньше, чем - < знак больше, чем - > Знаки, предназначенные для использования в качестве: разделитель информации - IS4 указателя конца сегмента разделитель информации - IS3 указателя начала сегмента и разделителя элементов данных разделитель информации - IS1 разделителя компонентных элементов данных ПРИМЕЧАНИЕ. Данный набор знаков не предназначен для передачи сообщении по телексной связи.
3.1. Элементы данных пользователей содержатся только в информационных сегментах. Служебные сегменты содержат служебные элементы данных, которые формируют структуру протокола обмена. Содержание служебных сегментов приведено в приложении 2. Иерархическая структура обмена
3.2. Сегмент UNA и служебные сегменты UNB - UNZ включаются в обмен в установленном порядке. В рамках одного обмена допускается передача нескольких функциональных групп или сообщений. В рамках одной функциональной группы допускается передача нескольких сообщений. Сообщение состоит из сегментов. Структура сегментов и их элементов данных описана в пп. 3.6 и 3.7. 3.3. Обмен должен иметь следующую структуру: согласованный набор ограничителей - UNA (условный); заголовок обмена - UNB (обязательный); заголовок функциональной группы - UNG (условный); заголовок сообщения - UNH (обязательный); сегменты данных пользователя - (если требуются); окончание сообщения - UNT (обязательный); окончание функциональной группы - UNE (условный); окончание обмена - UNZ (обязательный). ПРИМЕЧАНИЕ. Кроме перечисленных служебных сегментов, при необходимости, допускается использование служебного сегмента UNS для разделения зон сообщения. 3.4. В рамках каждого обмена существует иерархическая структура, которая позволяет осуществить контроль за данными и их идинтификацию. Эта структура приведена на схеме. 3.4.1. СОЕДИНЕНИЕ содержит один или несколько обменов. Технические протоколы, обслуживающие запуск, поддержание и окончание связи, а также другие операции, не являются предметом рассмотрения настоящего стандарта. 3.4.2. ОБМЕН включает: служебный сегмент UNA - согласованный набор ограничителей, который, если используется, определяет используемые в обмене синтаксические разделители и другие контрольные знаки; служебный сегмент UNB - заголовок обмена; функциональные группы, если они используются, или одно или несколько сообщений; служебный сегмент UNZ - окончание обмена. 3.4.3. ФУНКЦИОНАЛЬНАЯ ГРУППА включает: служебный сегмент UNG - заголовок функциональной группы; одно или несколько сообщений одного и того же типа; служебный сегмент UNE - окончание функциональной группы. 3.4.4 СООБЩЕНИЕ включает: служебный сегмент UNH - заголовок сообщения; один или несколько сегментов данных пользователя; служебный сегмент UNT - окончание сообщения. 3.4.5. СЕГМЕНТ ДАННЫХ ПОЛЬЗОВАТЕЛЯ включает: идентификатор (метку) сегмента; простые элементы данных или составные элементы данных в зависимости от использования. 3.4.6. ИДЕНТИФИКАТОР (МЕТКА) СЕГМЕНТА содержит: код сегмента, если он указывается; значение (я) повторения и вложения. 3.4.7. ПРОСТОЙ ЭЛЕМЕНТ ДАННЫХ содержит значение одного элемента данных. 3.4.8. СОСТАВНОЙ ЭЛЕМЕНТ ДАННЫХ содержит значения двух или более простых взаимосвязанных элементов данных, которые называются компонентными элементами данных. 3.4.9. Ниже приводятся примеры, описывающие обмен в виде последовательности сегментов: а) функциональная группа включает только одно сообщение: UNA UNB UNG UNH . . . Сегменты данных пользователя ...UNT UNE UNZ б) передача одного сообщения без функциональной группы: UNA UNB UNH . . . Сегменты данных пользователя . . . UNT UNZ в) передача одного сообщения без функциональной группы и без сегмента UNA: UNB UNH . . . Сегменты данных пользователя ... UNT UNZ 3.5. Пример, описывающий структуру сообщения, последовательность сегментов и групп сегментов в сообщении в соответствии с настоящими синтаксическими правилами, приведен в приложении 3. 3.6. Каждый сегмент данных пользователя должен иметь следующую структуру: идентификатор (метку) сегмента, который является обязательным и состоит из: кода сегмента, являющегося обязательным, разделителя компонентных элементов данных, являющегося условным; указания повторения или вложения, являющегося условным; разделитель элементов данных, являющийся обязательным; простые или составные элементы данных; знак окончания сегмента, являющийся обязательным. 3.7. Элемент данных в рамках сегмента данных пользователя должен иметь следующую структуру: простои элемент данных или составной элемент данных, обязательный или условный в зависимости от указаний в соответствующем справочнике сегментов и включающий: простые взаимосвязанные (компонентные) элементы данных, разделители компонентных элементов данных, являющиеся обязательными (при ограничении, указанном в примечании). ПРИМЕЧАНИЕ. Разделитель компонентного элемента данных не должен ставиться после последнего простого элемента данных, входящего в составной элемент данных. Разделитель элемента данных не должен ставиться после последнего элемента данных в сегменте.
4.1. При обмене в элементах данных, имеющих переменную длину, незначащие символы должны опускаться. Это правило распространяется в первую очередь на нули, предшествующие цифровому значению, и конечные пробелы. 4.2. Правило не распространяется на нуль, стоящий перед десятичной запятой (точкой), и на случаи значащих нулей - например в обозначении температуры, если это указано в описании данных. 4.3. При уплотнении данных в сообщениях должны соблюдаться правила, приведенные и пп. 4.3.1-4.3.5. Примечание. В приведенных далее примерах «Tag» означает идентификатор (метку) начала сегмента, «DE» - элемент данных и «СЕ» - составной элемент данных. В примерах используются разделители уровня А. 4.3.1. Условные сегменты, не содержащие данных, исключаются, в том числе исключаются и идентификаторы начала сегмента. 4.3.2. Порядок элементов данных и сегменте должен быть задан в определенной последовательности. Если условный элемент данных опускается в начале или середине сегмента, то его позиция обозначается путем сохранения разделителя данного элемента данных. Пример.
4.3.3. Если один или несколько условных элементов данных опущены в конце сегмента то данный сегмент может быть сокращен с помощью указателя конца сегмента, т.е. разделители пропущенных элементов данных не должны передаваться. Пример.
4.3.4. Простые компонентные элементы данных, идентифицируются по их последовательности в составном элементе данных. Если опускается условный компонентный элемент данных, то его позиция обозначается путем сохранения знака разделения компонентных элементов данных. Пример.
4.3.5. Если один или несколько условных компонентных элементов данных в конце составного элемента данных опускаются, то это отсечение указывается с помощью разделителя элементов данных, или, если эти элементы находятся в конце сегмента, с помощью указателя конца сегмента. Пример.
В обоих случаях составные элементы данных сокращены, в первом случае это показано разделителем элементов данных, а во втором - указателем конца сегмента.
5.1. Для сообщений определенного типа должен быть использован один из двух методов указания на повторение сегментов, а именно: прямое указание на повторение или косвенное указание на повторение. Выбор конкретного метода осуществляется при составлении сообщения. В одном и том же сообщении не допускается использовать одновременно оба метода. 5.2. Указание на повторение может быть прямым, если оно присутствует в идентификаторе (метке) сегмента в виде компонентного элемента данных, или косвенным на основе последовательности сегментов, указанной в соответствующем определении сообщения. 5.3. Сегменты уровня 0 (приложение 3) не должны повторяться и их идентификаторы не содержат указания на повторение. 5.4. Служебные сегменты (приложение 2), за исключением сегмента ТХТ, не должны повторяться и их идентификаторы не содержат указания на повторение. 5.5. При использовании метода прямого указания на повторение в идентификаторе сегмента первый компонентный элемент данных должен быть кодом сегмента, а последний из следующих компонентных элементов данных должен указывать номер повторения сегмента в сообщении. 5.6. При использовании метода косвенного указания на повторение сегменты должны появляться в сообщении в порядке, указанном в описании типа сообщения.
6. ПОВТОРЕНИЕ ЭЛЕМЕНТОВ ДАННЫХ 6.1. Элементы данных (DE) не должны повторяться в сегменте большее число раз, чем это предусмотрено в справочнике сегментов. Если они повторяются меньшее число раз, то применяются правила, содержащиеся в пп. 4.3.2-4.3.5. Пример
6.2. Допускается представлять повторяющиеся элементы в виде компонентных элементов данных (СЕ) в составных элементах, что позволяет проводить сокращение с помощью разделителей элементов данных. Эго правило применяется также к определенным повторяющимся последовательностям элементов данных, например, в отношении последовательности СЕ1:СЕ2:СЕ3. Пример
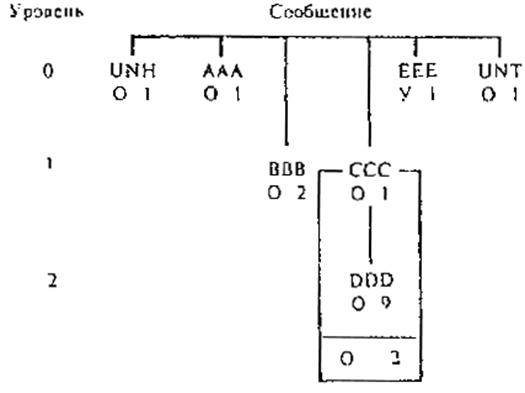
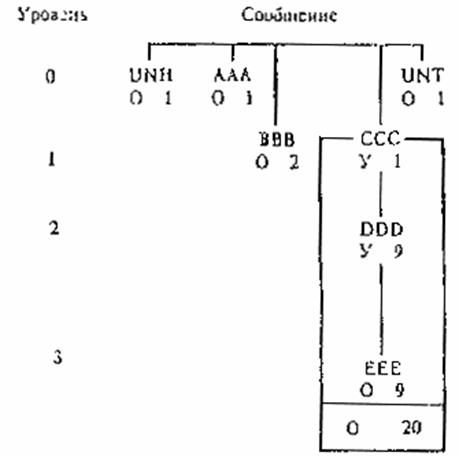
7. ПОСЛЕДОВАТЕЛЬНОЕ РАЗМЕЩЕНИЕ СЕГМЕНТОВ В СООБЩЕНИИ 7.1. В структуре сообщения сегмент может зависеть от другого сегмента, находящегося на более высоком иерархическом уровне и, следовательно, будет вложен в этот сегмент. Для сообщений такого типа используются методы прямого и косвенного указания о вложении. Выбор конкретного метода осуществляется при составлении сообщения. В одном и том же сообщении не допускается использовать одновременно оба метода. 7.2. Указание о вложении может быть прямым, если оно присутствует в идентификаторе (метке) сегмента в виде компонентного элемента данных, или косвенным на основе последовательности сегментов, указанной в соответствующем определении сообщения. 7.3. Служебные сегменты (приложение 2) и другие сегменты уровня 0 (приложение 3) не должны вкладываться, при этом их идентификаторы не должны содержать указания о вложении. 7.4. При использовании метода прямого указания о вложении в идентификаторе сегмента первый компонентный элемент данных должен быть кодом сегмента, а следующие за ним условные компонентные элементы данных должны указывать на уровень иерархии и на номер повторения сегмента в рамках сегмента более высокого уровня. 7.5. Число компонентных элементов данных, используемых для этой цели, зависит от иерархического уровня, на котором находится сегмент в схеме структуры сообщения (приложение 3). Следующий после кода сегмента компонентный элемент данных, предназначенный для первого контрольного счета, должен использоваться, если сегмент находится на первом уровне; второй компонентный элемент данных должен использоваться, если сегмент находится на втором уровне; третий - если сегмент находится на третьем уровне и т.д. 7.6. Если условный сегмент более высокого уровня не используется в конкретном случае, то при указании уровня иерархии должны присутствовать разделители компонентных элементов данных для неиспользуемых уровней, а данный сегмент должен находиться перед сегментами, включающими указание на этот уровень. 7.7. В приведенных ниже примерах сообщений используются прямое указание на повторение и вложение, а также разделители уровня А. Подробное объяснение схемы приведено в приложении 3. Пример 1. Сообщение с одним уровнем вложения обязательного сегмента.
Сегменты Объяснения UNH данные’ ААА + данные’ ВВВ:1 + данные’ Элемент 1 ВВВ ВВВ:2 + данные’ Элемент 2 ВВВ ССС:1 + данные’ Элемент 1 CCC DDD:1:1 + данные’ Элемент 1 DDD в CCC (1) DDD:1:2 + данные’ Элемент 2 DDD в CCC (1) ССС:2 + данные’ Элемент 2 ССС DDD:2:1 + данные’ Элемент 1 DDD в CCC (2) EЕЕ + данные’ UNT + данные’ В виде строки сообщение выглядит следующим образом: UNH+данные’AAA+данные’BBB:l+данные’BBB:2+данные’CCC:1+данные’DDD:1:1+данные’DDD:1:2+данные’ССС:2+данные’ DDD:2:1+данные’ЕЕЕ+данные’UTN+данные’ Пример 2 Сообщение с двумя уровнями вложения условного сегмента товаров (EEE) в коробках (DDD), помещенных в контейнеры (CCC).
Сегменты Объяснения UNH+данные’ ААА+данные’ ВВВ:1+данные’ Элемент 1 ВВВ ВВВ:2+данные’ Элемент 2 ВВВ ЕЕЕ:::1+данные’ Элемент 1 ЕЕЕ без DDD и CCC ЕЕЕ:::2+данные’ Элемент 2 ЕЕЕ без DDD и CCC ССС:1+данные’ Первое появление CCC DDD:1:1+даные’ Первое появление DDD в рамках CCC (1) ЕЕЕ:1:1:1+данные’ ЕЕЕ (1) в рамках DDD (1) в рамках CCC (1) ЕЕЕ:1:1:2+данные’ ЕЕЕ (2) в рамках DDD (1) в рамках CCC (1) DDD:1:2+данные’ DDD (2) в рамках CCC (1) ЕЕЕ:1:2:1+данные’ ЕЕЕ (1) в рамках DDD (2) в рамках CCC (1) ССС:2+данные’ CCC (2) ЕЕЕ:2::1+данные’ ЕЕЕ (1) в рамках CCC (2) без DDD UNT+данные’ В виде строки сообщение выглядит следующим образом: UNH+данные’ААА+данные’ВВВ:1+данные’ВВВ:2+данные’ЕЕЕ:::1+данные’ЕЕЕ:::2+данные’ССС:1+данныеDDD:1:1+данные’ ЕЕЕ:1:1:1+данные’ЕЕЕ:1:1:2+данные’DDD:1:2+данные’ ЕЕЕ:1:2:1+данные’ССС:2+данные’ЕЕЕ:2::1+данные’UNT+данные’ 7.8. Порядок расположения сегментов, определенный в схеме структуры сообщения (сверху вниз, слева направо), должен соблюдаться. При использовании метода косвенного указания о вложении сегментов никаких дополнительных указаний для обработки не требуется.
8. ПРЕДСТАВЛЕНИЕ ЗНАЧЕНИЙ ЦИФРОВЫХ ЭЛЕМЕНТОВ ДАННЫХ 8.1. Согласно ГОСТ 8.417 (ИСО 31/0) десятичный знак представляется в виде запятой «,». Разрешается также использовать «.». Оба знака входят в наборы уровней А и В, определенных в разд. 2 настоящего стандарта, и могут использоваться. 8.2. При использовании набора ограничителей сегмента UNA третий знак определяет знак, используемый в обмене в качестве десятичного знака. В этом случае исключается возможность альтернативного использования запятой или точки. 8.3. Десятичный знак не должен рассматриваться в качестве значащей позиции при расчете максимальной длины поля элемента данных. 8.4. При передаче десятичного знака до и после десятичного знака должна быть, по крайней мере, одна цифра. Для значений, выраженных целыми числами, не должен использоваться десятичный знак и десятичные нули, если не требуется указать степень точности. Пример Предпочтительное представление: 0,5 или 2 или 2,0 Разрешенное представление: 0,5 или 2 или 2.0 Запрещенное представление: ,5 или .5 или 2, или 2. 8.5. В обмене данных разделители триад не используются. Пример. Разрешенное представление: 2500000 Запрещенное представление: 2,500,000 или 2.500.000 или 2 500 000 8.6. Значения цифровых элементов данных считаются положительными, включая случаи, когда в описании элемента данных подразумевается, что он имеет отрицательное значение. 8.7. Если указываемое значение является отрицательным, то перед ним следует передавать знак минус, например: -112. 8.8. При расчете максимальной длины поля элемента данных знак минус не должен учитываться при подсчете числа знаков в значении.
ПРИЛОЖЕНИЕ 1 ТЕРМИНЫ, ИСПОЛЬЗУЕМЫЕ В НАСТОЯЩЕМ СТАНДАРТЕ, И ИХ ПОЯСНЕНИЯ В приложении приведена терминология, соответствующая аналогичным понятиям в стандартах ИСО, а также содержащаяся в настоящем стандарте. Таблица 1
ПРИЛОЖЕНИЕ 2 СПРАВОЧНИК СЛУЖЕБНЫХ СЕГМЕНТОВ В справочнике служебных сегментов используется следующая система обозначений: справочный код - цифровой код элемента данных, указанный в стандарте ИСО 7372. Если код содержит букву S, то он относится к составному элементу данных; наименование данных - наименование СОСТАВНОГО ЭЛЕМЕНТА ДАННЫХ заглавными буквами, наименование ЭЛЕМЕНТА ДАННЫХ заглавными буквами, наименование КОМПОНЕНТНОГО ЭЛЕМЕНТА ДАННЫХ строчными буквами; представление значений данных: a - алфавитные знаки, n - цифровые знаки, an - алфавитно-цифровые знаки, a3 - 3 алфавитных знака постоянной длины, n3 - 3 цифровых знака постоянной длины, an3 - 3 алфавитно-цифровых знака постоянной длины, a ... 3 - до 3 алфавитных знаков, n ... 3 - до 3 цифровых знаков, an ... 3 - до 3 алфавитно-цифровых знаков О - обязательный элемент, У - условный элемент. Следует отметить, что компонентный элемент данных в условном составном элементе данных может быть помечен как обязательный. Это означает, что если составной элемент данных используется, то этот компонентный элемент данных должен присутствовать обязательно. СЕГМЕНТ UNA - согласованный набор органичителей Функция сегмента - определение знаков, выбранных для использования в качестве разделителей и указателей в остальной части обмена. Согласованный набор ограничителей, используемых в последующем обмене дачными, должен передаваться перед каждым заголовком обмена данными. Сегмент имеет строго фиксированную длину из 9 знаков. Первыми тремя знаками являются буквы UNA. за которыми непосредственно следуют 6 знаков, выполняющих функции в данном синтаксисе, приведенные в табл. 2. Таблица 2
СЕГМЕНТ UNB - заголовок обмена Функция сегмента - запуск, идентификация и указание параметров обмена. Элементы данных, содержащиеся в сегменте, приведены в табл. 3. Таблица 3
СЕГМЕНТ UNG - окончание обмена Функция сегмента - заканчивает обмен и проверяет его завершенность. Элементы данных, содержащиеся в сегменте, приведены в табл. 4. Таблица 4
СЕГМЕНТ UNG - заголовок функциональной группы Функция сегмента - возглавляет, идентифицирует и описывает функциональную группу. Элементы данных, содержащиеся в сегменте, приведены а табл. 5. Таблица 5
СЕГМЕНТ UNE - окончание функциональной группы Функция сегмента - заканчивает и проверяет завершенность обмена. Элементы данных, содержащиеся в сегменте, приведены и табл. 6. Таблица 6
СЕГМЕНТ UNH - заголовок сообщения Функция сегмента - возглавляет, идентифицирует и описывает сообщение. Элементы данных, содержащиеся в сегменте, приведены в табл. 7. Таблица 7
СЕГМЕНТ UNT - окончание сообщения Функция сегмента - заканчивает сообщение и проверяет его завершенность. Элементы данных, содержащиеся в сегменте, приведены в табл. 8. Таблица 8
СЕГМЕНТ ТХТ - сегмент текста Функция сегмента - представление информации в дополнение к информации, содержащейся в других сегментах служебного сообщения, если это необходимо. Элементы данных, содержащиеся в сегменте, приведены в табл. 9. Примечание. Сегмент не может быть обработан автоматически. Следует включать только в случае необходимости. Как правило, этот сегмент является условным сегментом. Сегмент может быть повторен такое число раз, какое указано в спецификации сообщения, но не более пяти раз. Таблица 9
СЕГМЕНТ UNS - сегмент разделения зон Функция сегмента - разделение таких зон в сообщении, как заголовок, подобная информация и обобщения. Элементы данных, содержащиеся в сегменте приведены в табл. 10. Примечание. Сегмент используется составителями сообщении в случае, когда необходимо избежать двусмысленности. Обязательно применяется лишь в том случае, если это определено для сообщения данного типа. Таблица 10
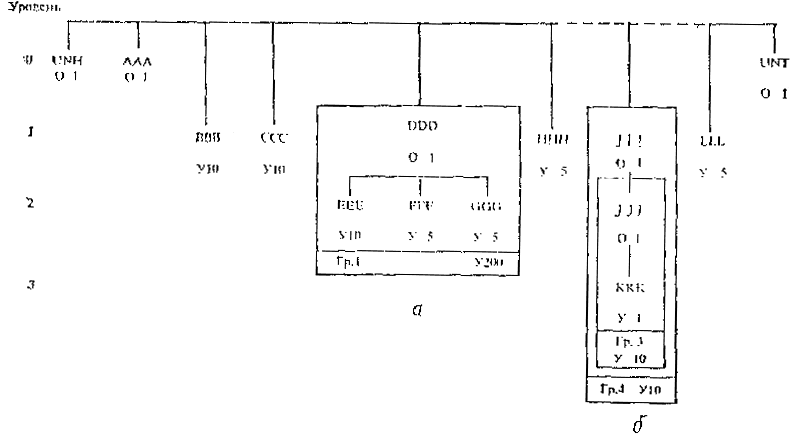
ПРИЛОЖЕНИЕ 3 ПОСЛЕДОВАТЕЛЬНОСТЬ СЕГМЕНТОВ И ГРУПП СЕГМЕНТОВ В СООБЩЕНИИ Сегменты, используемые в сообщении, должны появляться в последовательности (сверху вниз, слева направо), указанной в схеме структуры сообщения. Сегменты идентифицируются с помощью своих кодов. Условия их включения в сообщение, т.е. их статус, указываются непосредственно под кодами с помощью буквы О, означающей «обязательное», или У, означающей «условно». Число появлений сегмента в каждом случае указывается сразу же после этого. Обязательный сегмент должен появиться, по крайней мере, один раз, но не больше, чем это указано. Условный сегмент может быть опущен или может появиться указанное число раз. Если сегмент вкладывается в другой сегмент, то он размещается на схеме на следующем, более низком уровне. Сегменты нулевого уровня не повторяются и не содержат вложенных сегментов. Два или несколько сегментов могут быть сгруппированы. На схеме это показывается в виде рамки. Группа и сегменты, обведенные рамкой, могут быть, обязательными и условными и могут появляться указанное число раз. Группа может включать одну или несколько других групп более низкого уровня (в приведенном примере группы 3 и 4). Сообщение начинается сегментом UNH «Заголовок сообщения» и закачивается сегментом UNT «Окончание сообщения». Пример. Части сообщения условного типа.
а - условная группа сегментов 1 может повторяться до 200 раз; б - условная группа сегментов 3 внутри группы 4 Сегменты могут быть также представлены следующим образом:
Порядок обработки сегментов следующий (группа 1 появляется два раза, другие группы - один раз, сегменты не повторяются): UNH, АAА, ВВВ, ССС, DDD, ЕЕE, FFF, GGG, DDD, ЕЕЕ, FFF, GGG, НHН,..., III, JJJ, ККК,..., LLL, UNT.
ПРИЛОЖЕНИЕ 4 СПРАВОЧНЫЕ НОРМАТИВНЫЕ ДОКУМЕНТЫ ИСО 31/0-81 «Общие принципы, касающиеся количества, единиц и условных обозначений». ИСО 646-83 «Обработка информации. Набор семибитных кодированных знаков ИСО для обмена информацией». ИCO 2382/1-84 «Обработка данных. Словарь. Часть 01: Основные термины». ИСО 2382/4-87 «Обработка данных. Словарь. Раздел 04: Организация данных». ИСО 6523-84 «Обмен данными. Структура для идентификации организации». ИСО 7372-80 «Электронный обмен данными в управлении, торговле и на транспорте. Справочник элементов внешнеторговых данных». ИСО 7498-84 «Взаимодействие открытых систем. Базовая справочная модель». ИCO 6937/2-83 «Обработка информации. Набор кодированных знаков для передачи текста». ИСО 8859-87 «Обработка информации. Набор восьмибитных одноразрядных кодированных графических знаков».
ИНФОРМАЦИОННЫЕ ДАННЫЕ 1. ВНЕСЕН Министерством внешних экономических связей СССР 2. ПОСТАНОВЛЕНИЕМ Государственного комитета СССР по управлению качеством продукции и стандартам от 30.11.89 № 63 введен в действие государственный стандарт СССР, в качестве которого непосредственно применен международный стандарт ИСО 9735-88 «Электронный обмен данными в управлении, торговле и на транспорте (ЭДИФАКТ). Синтаксические правила», с 01.01.92 3. ССЫЛОЧНЫЕ НОРМАТИВНО-ТЕХНИЧЕСКИЕ ДОКУМЕНТЫ
* Государственный стандарт находится в стадии разработки
ГОСТ 6.20.1-90 (ИСО 9735-88) Электронный обмен данными в управлении, торговле и на транспорте (ЭДИФАКТ) Синтаксические правила
|
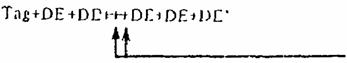 Два
элемента данных опущены
Два
элемента данных опущены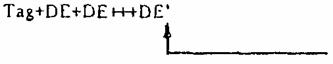 В примере, приведенном в
В примере, приведенном в
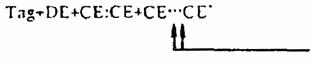 В последнем составном элементе данных опущены два компонентных элемента данных.
В последнем составном элементе данных опущены два компонентных элемента данных. В примере, приведенном в
В примере, приведенном в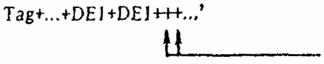 Опущены два из четырех возможных повторений элемента данных
Опущены два из четырех возможных повторений элемента данных  Сокращение с помощью разделителя элементов данных после двух
последовательностей.
Сокращение с помощью разделителя элементов данных после двух
последовательностей.